原文:
翻译:
2018年 4月 24日 星期二
针对运行频率高的脚本生成的代码,v8会对其进行代码缓存。从Chrome 66开始,我们通过在顶层执行(top-level execution)之后生成缓存的方法,缓存了更多的代码。这导致初始化期间的解析和编译耗时减少20%-40%。
背景
v8使用两种缓存方式来缓存生成的代码,以便后续使用。第一种是每个v8的实例(instance)都有的内存缓存。首次编译生成的代码会使用这种缓存方式,以源码字符串为key。可以在同一个v8实例中重用。(还没弄清楚这个说的哪个流程的缓存)第二种是磁盘缓存,将生成的代码序列化保存 到本地磁盘以备将来重用。这种缓存方式,不针对特定的v8实例,可以在不通的实例中使用。此博文重点介绍chrome中使用的,第二种缓存方式。(其他的嵌入器也使用了这类缓存,不仅限与chrome。但是本文章,主要关注chrome中的使用情况)
Chrome将生成的代码序列化保存在磁盘缓存,以脚本url地址为索引key。当加载一个脚本时,chrome会检查磁盘缓存。如果脚本已经被缓存,chrome会将序列化的数据作为编译请求的一部分,传递给v8。v8会反序列化数据,而不是去解析和编译脚本。还需要其他的检查以确保缓存有效。(例如版本号不匹配会导致缓存失效)
实际数据显示代码缓存命中率(针对可以缓存的脚本)高达86%。虽然这些脚本的缓存命中率很高,但是我们为每个脚本缓存的代码量并不是很高。我们的分析表明,增加代码缓存的量会减少解析和编译javaScript代码花费时间40%左右。
增加代码缓存的量
在之前的方案中,代码缓存和脚本编译请求耦合在一起。
内嵌v8的应用(Embedders)可以要求v8在顶层编译(top-level compliation) 一个新js脚本的时候生成代码并序列化它们。编译脚本完成后,V8返回序列化的代码。当Chrome再次请求相同的脚本时,v8从缓存中提取序列化的代码对其进行反序列化。v8完全避免重复编译已经在缓存中的函数。这些应用场景如下图所示:
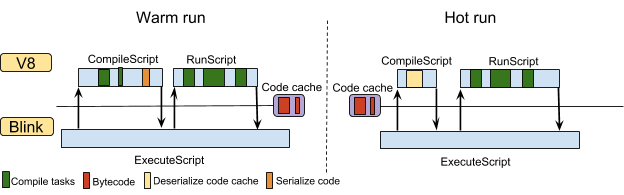
v8仅编译顶层执行中,那些预期会立即执行的函数,其他的函数均标记为延迟编译(Lazy compilation)。这有助于避免编译不需要的函数,来改善页面加载时间,但这意味着序列化的代码仅仅只包含了急需提前编译的函数代码。
在Chrome 59之前,我们必须在任何执行开始之前生成代码缓存。早期的v8基础编译器(full-codegen)为执行的上下文生成专用代码。Full-codegen使用代码补丁的方式对特定执行上下文的操作进行快速补丁。这些的代码无法通过删除其他执行上下文中生成的专用代码,然后很容易被序列化。
自从Chrome 59开始启动Lgnition,这个限制就不在必要了。lgn使用数据驱动内联缓存对当前执行的上下文进行快速补丁。这些独立于上下文的信息之外的数据被存储在反馈向量中,和生成的代码是分开的。这使得在执行脚本后生成代码缓存成为可能。当我们执行脚本,越来越多的函数(之前被标记位lazy compile)被编译,我门就可以缓存更多的代码。
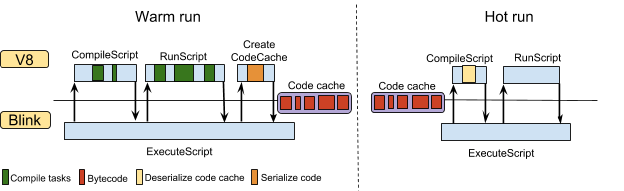
V8导出了一个新的API,ScriptCompiler::CreatecodeCache,用于独立编译请求之外请求代码缓存。在编译时请求代码缓存已经被废弃,在v8 6.6以上不能使用。从Chrome 66版本开始,chrome使用这个API,在顶层执行(top-level execute)之后请求代码缓存。接下来的图显示了新代码缓存的场景。代码缓存是发生在顶层执行(top-level execute)之后,因此就包含了那些只有在真实执行才被编译的函数代码。在后续的运行中(下图中 hot run),避免编译顶层执行中编译过的函数。
结果
我们使用内部真实世界(real-word benchmarks)来对这个功能特性进行评估。下图显示了对比早起的缓存系统,解析和编译时间的降低情况。在大部分页面上解析和编译时间减少了20%-40%。
v8_Blog_201804_improved-code-caching_files/Image [2].png)
v8_Blog_201804_improved-code-caching_files/Image [3].png)
外部真实事件的数据也显示了类似的结果,在桌面和移动平台上编译时长减少了20%-40%。在Android平台上,这个优化也带来了顶层页面加载指标降低1%-2%,也就是网页到达可交互状态的消耗。我们也监控了Chrome的内存和磁盘消耗,并没有发现任何明显的性能倒退。